SQLite Technology Guide
This document provides background information on the internal workings of SQLite, the database engine used by Symbian SQL.
Purpose
SQLite is a fast efficient database engine freely available to anyone to use in any way the want. The information in this document provides important background information that you will need to know in order to make the most of Symbian SQL and SQLite on Symbian platform.
Intended audience:
This document is intended to be used by Symbian platform developrs and third party application developers.
The architecture and operation of SQLite
The figure below shows the major modules within SQLite. SQL statements that are to be processed are sent to the SQL Compiler module which does a syntactic and semantic analysis of the SQL statements and generates bytecode for carrying out the work of each statement. The generated bytecode is then handed over to a Virtual Machine for evaluation.
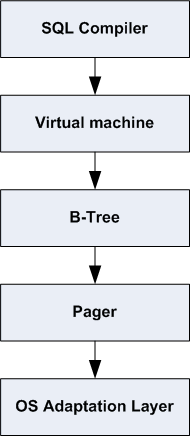
The Virtual Machine considers the database to be a set of B-Trees, one B-Tree for each table and one B-Tree for each index. The logic for creating, reading, writing, updating, balancing and destroying B-Trees is contained in the B-Tree module.
The B-Tree module uses the Pager module to access individual pages of the database file. The Pager module abstracts the database file into zero or more fixed-sized pages with atomic commit and rollback semantics.
All interaction with the underlying file system and operating system occurs through the OS Adaptation Layer.
SQL Statements as Computer Programs
A key to understanding the operation of SQLite, or any other SQL relational database engine, is to recognize that each statement of SQL is really a small computer program.
Users of SQL database engines sometimes fail to grasp this simple truth because SQL is a peculiar programming language. In most other computer languages the programmer must specify exactly how a computation is to take place. But in SQL the programmer specifies what results are needed and lets the SQL Compiler worry about how to achieve them.
All SQL database engines contain a SQL Compiler of some kind. The job of this compiler is to convert SQL statements into procedural programs for obtaining the desired result. Most SQL database engines translate SQL statements into tree structures. The Virtual Machine modules of these databases then walk these tree structures to evaluate the SQL statements. A few SQL database engines translate SQL statements into native machine code.
SQLite takes an intermediate approach and translates SQL statements into small programs written in a bytecode language. The SQLite bytecode is similar in concept to Java bytecode, the parrot bytecode of Perl, or to the p-code of the UCSD Pascal implementation. SQLite bytecode consists of operators that work with values contained in registers or on a stack. Typical bytecode operators do things like:
-
Push a literal value onto the stack
-
Pop two numbers off of the stack, add them together and push the result back onto the stack
-
Move the top element of the stack into a specific memory register
-
Jump to a specific instruction if the top element of the stack is zero
The SQLite bytecode supports about 125 different opcodes. There is a remarkable resemblance between SQLite bytecode and assembly language. The major difference is that SQLite bytecode contains a few specialized opcodes designed to facilitate database operations that commonly occur in SQL.
Just as you do not need to understand the details of x86 or ARM7 assembly language in order to make effective use of C++, so also you do not need to know any of the details of SQLite bytecode in order to make the best use of SQLite. The reader need only recognize that the bytecode is there and is being used behind the scenes.
Those who are interested can peruse the definitions of the bytecodes in the SQLite documentation. But the details of the various bytecodes are not important to making optimal use of SQLite and so no further details on the bytecodes will be provided in this document.
A SQLite database file consists of one or more b-trees. Each table and each index is a separate b-tree.
A b-tree is a data structure discovered in 1970 by Rudolf Bayer and Edward McCreight and is widely used in the implementation of databases. B-trees provide an efficient means of organizing data stored on an external storage device with fixed-sized blocks, such as a disk drive or a flash memory card. Each entry in a b-tree has a unique key and arbitrary data. The entries are ordered by their key which permits efficient lookup using a binary search. The b-tree algorithm guarantees worst-case insert, update, and access times of O(log N) where N is the number of entries.
In SQLite, each table is a separate b-tree and each row of the table is a separate entry. The b-tree key is the RowID or INTEGER PRIMARY KEY for the row and other columns in the row are stored in the data for the b-tree entry. Tables use a variant of the b-tree algorithm call b+trees in which all data is stored on the leaves of the tree.
Indexes are also stored as b-trees with one entry in the b-tree for each row of the table being indexed. The b-tree key is composed of the values for the columns being indexed followed by the RowID of the corresponding row in the table. Indexes do not use the data part of the b-tree entry. Indexes use the original Bayer and McCreight b-tree algorithm, not b+trees as tables do.
The number of pages in a b-tree can grow and shrink as information is inserted and removed. When new information is inserted and the b-tree needs to grow, the B-Tree Module may reuse pages in the database that have fallen into disuse or it may ask the Pager module to allocate new pages at the end of the database file to accommodate this growth. When a b-tree shrinks and pages are no longer needed, the surplus pages are added to a free-list to be reused by future page requests. The B-Tree module takes care of managing this free-list of unused pages.
The Pager module (also called simply “the pager”) manages the reading and writing of raw data from the database file such that reads are always consistent and isolated and so that writes are atomic.
The pager treats the database file as a sequence of zero or more fixed-size pages. A typical page size might be 1024 bytes. Within a single database all pages are the same size. The first page of a database file is called page 1. The second is page 2. There is no page 0. SQLite uses a page number of 0 internally to mean “no such page”.
When the B-Tree module needs a page of data from the database file, it asks for the page by number from the pager. The pager then returns a pointer to the requested data. The pager keeps a cache of recently accessed database pages so in many cases no disk I/O has to occur to fulfil a page request.
The B-Tree module notifies the pager before making any changes to a page and the pager then saves a copy of the original page content in a rollback journal file. The rollback journal is used to restore the database to its original state if a ROLLBACK occurs.
After making changes to one or more pages, the B-Tree Module may ask the pager to commit those changes. The pager then goes through a carefully designed sequence of steps that ensure that changes to the database are atomic. If the update process is interrupted by a program crash, a system crash, or even a power failure, the next time the database is accessed it will appear that either all the changes were made or else none of them.
A SQLite database file consists of one or more fixed-sized pages. The first page contains a 100-byte header that identifies the file as a SQLite database and which contains operating parameters such as the page size, a file format version number, the first page of the free-list, flags indicating whether or not autovacuum is enabled, and so forth.
The content of the database is stored in one or more b-trees. Each b-tree has root page which never moves. If the table or index is small enough to fit entirely on the root page, then that one page contains everything there is to know about the table or index. But most tables and indexes require more space and additional pages must be allocated.
The root page contains pointers (actually page numbers) to the other pages in the b-tree. So given the root page of a b-tree that implements a table or index, the B-Tree module is able to follow pointers to locate any entry in the b-tree and thus any row in the corresponding table or index.
Every SQLite database contains a master table which stores the database schema. Each row of the master table holds information about a single table, index, view or trigger, including the original CREATE statement that created that table, index, view or trigger. Rows that define tables and indexes also record the root page number for the b-tree that stores the table or index. The root page of the master table is always page 1 of the database file, so SQLite always knows how to locate it. And from the master table it can learn the root page of every other table and index in the database and thus locate any information in the database.
An Example of SQLite in Operation
This is what happens inside SQLite during a typical usage scenario: When the SQL server instructs SQLite to open a database, the SQLite library allocates a data structure to hold everything it will ever need to know about that database connection. It also asks the pager to open the database file, but does not immediately try to read anything or even verify that the file is a valid database.
The first time you actually try to access the database, SQLite will look at the 100-byte header of the database file to verify that the file is a SQLite database and to extract operating parameters such as the database page size.
After checking the header SQLite opens and reads the entire master table. Recall that the master table contains entries for every table, index, view and trigger in the database and that each entry includes the complete text of the CREATE statement that originally created the table, index, view or trigger.
SQLite parses these CREATE statements in order to rebuild an internal symbol table holding the names and properties of all tables, indexes, triggers and views in the database schema.
Among the values stored in the header of the database is a 32-bit schema cookie . The schema cookie is changed whenever the database schema is modified by creating or dropping a table, index, trigger, or view.
When SQLite parses the database schema into its internal symbol table, it remembers the schema cookie. Thereafter, whenever SQLite goes to access the database file, it first compares the schema cookie that it read when it parsed the schema to the current schema cookie value.
If they match, everything continues normally, but if the schema cookie has changed that means that some other thread or process may have modified the database schema. When that happens, SQLite has to throw out its internal symbol table and reread and re-parse the entire database schema in order to figure out what might have changed.
RSqlStatement ’s RSqlStatement::Prepare() API is used to interface with SQLite’s SQL Compiler. The Prepare() API triggers tokenizing, parsing, and compilation of a SQL statement into the internal bytecode representation that is used by the Virtual Machine. The generated bytecode is stored in an object returned by SQLite often referred to as a prepared statement .
After compiling a SQL statement into a prepared statement you can pass it to the Virtual Machine to be run. This is the job of RSqlStatement ’s RSqlStatement::Next() and RSqlStatement::Exec() APIs. These interfaces cause the bytecode contained in the prepared statement to be run until it either completes or until it hits a breakpoint.
A breakpoint is hit whenever a SELECT statement generates a row of result that needs to be returned. When a breakpoint is hit SQLite returns control to the caller.
The bytecode in a prepared statement object is such that whenever a breakpoint occurs, a single row of the result of a SELECT statement is contained on the stack of the Virtual Machine. At this point column accessor functions can be used to retrieve individual column values.
RSqlStatement::Reset() can be called on a prepared statement at any time. This rewinds the program counter of the Virtual Machine back to the beginning and clears the stack, thus leaving the prepared statement in a state where it is ready to start over again from the beginning.
RSqlStatement ’s RSqlStatement::Close() API is merely a destructor for the prepared statement object. It calls Reset() to clear the virtual machine stack if necessary, deallocates the generated bytecode, and frees the container object.
Similarly, RSqlDatabase’ s Close() API is just a destructor for a server-side object created by SQLite when the database was opened. SQLite asks the pager module to close the database file, clears the symbol table, and de-allocates all associated memory.
Copyright ©2010 Nokia Corporation and/or its subsidiary(-ies).
All rights
reserved. Unless otherwise stated, these materials are provided under the terms of the Eclipse Public License
v1.0.