Locking
This document describes SMP locks and outlines the need of introducing locks in the code.
Locks are used to synchronize the data between threads in the kernel. They can be also used to synchronize access to data in user side threads In SMP, threads are executed in parallel, which means that if locks are not applied to the code it could result in a race condition. Race conditions lead to system crashes and data corruptions.
Locking Granularity
An important property of a lock is its granularity. The granularity is a measure of the amount of data the lock is protecting. There are two different granularities for locks:
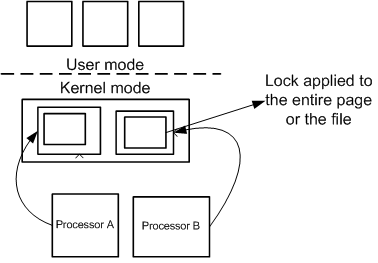
Coarse-Grained Locks enclose a large area of shared code or multiple areas of unrelated data. The lock reduces the number of threads that run concurrently resulting in serial execution making the code behave like a single thread process. Coarse locks are applied in parallel. One lock can be applied to each kernel subsystem.
The following diagram illustrates how a Coarse-Grained Lock covers many parts of code. It not only simplifies the locking action itself but also frees developers from having to load all the members of a code in order to lock them. In order to get concurrency in the operating system, the operating system must allow more than one process (or interrupt) to execute at the same time. To do this, we divide the OS into sections and give each section a lock. For a small number of processors, we only need a small number of locks, each covering a large region of the OS. This model of coarse-grained locking provides good scaling on small numbers of processors.
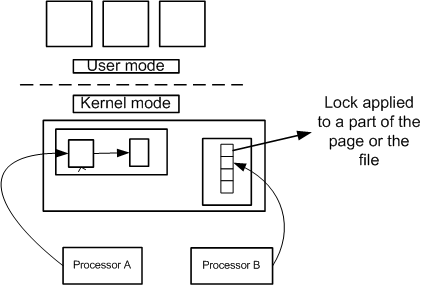
Fine-Grained Locks enclose a small area of code for example a data structure. These locks are added to the code and the user must remember to release the lock. Fine locks are error prone.
As the number of processors increases, the number of locks also increases. The following diagram illustrates how fine locks are applied to data. In other words, fine locks protect individual data structures or even parts of data structures. All those locks add instructions and data. To do this, we divide the OS into sections and divide the section into small pieces of code and apply lock for each piece of code. Fine-grained locking can result in near perfect scaling.
Type of Locks
TSpinLock is the lightest weight lock available kernel side. If a process attempts to acquire a spinlock and one is not available, the process will keep trying (spinning) until it can acquire the lock. Spinlocks should be used to lock data in situations where the lock is not held for a long time.
RFastLock is the lightest weight lock available user side. There is no priority inheritance. This is a layer over a standard semaphore, and only calls into the kernel side if there is contention.
RMutex is used to serialize access to a section of re-entrant code that cannot be executed concurrently by more than one thread. A mutex object allows one thread into a controlled section, forcing other threads which attempt to gain access to that section to wait until the first thread has exited from that section.
RSemaphore is used for Inter Process Communication (IPC), they are similar in performance to RMutex. RSemaphore locks are used when the lock must be held for a long time. These locks put the thread into sleep mode and are used to synchronize user contexts.
Copyright ©2010 Nokia Corporation and/or its subsidiary(-ies).
All rights
reserved. Unless otherwise stated, these materials are provided under the terms of the Eclipse Public License
v1.0.