Data Integrity and Memory Barriers
This topic explains how memory barriers are used to maintain data integrity in a multi-CPU system with shared memory and I/O.
Introduction
When a thread is executed on a single CPU system, there is an order to the read/write operations to shared memory and I/O. Since read and write operations cannot occur at the same time, the integrity of the data is maintained.
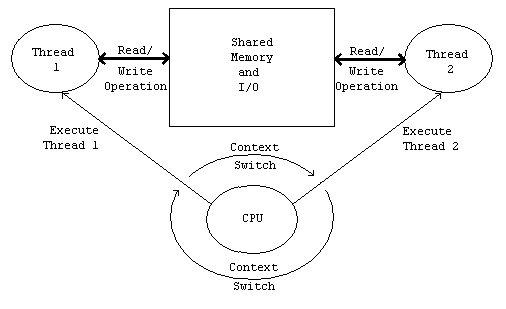
Figure 1 shows how shared memory and I/O is handled on a single CPU system. The CPU switches between threads (this is called a context switch). Because only one thread can be executed at once, read and write operations to shared memory and I/O cannot occur at the same time. Hence the integrity of the data can be maintained.

Figure 2 shows how shared memory and I/O is handled on a multi CPU system. In this system, it is possible that the read/write order will not be the one expected. This is due performance decisions made by the hardware used to interface memory to the rest of the system. Without some form of synchronisation mechanism in place, data corruption will occur.
To safeguard the integrity of data, a new synchronisation method known as a memory barrier has been implemented.
Memory Barriers
Memory barriers are used to enforce the order of memory access. They are also known as membar, memory fence or a fence instruction.
An example of their use is :
thread 1: a = 1; b = 1; thread 2: while (b != 1); assert(a==1);
In the above code on a single-core system, the condition in the assert statement would always be true, because the order of read/write operations can be guaranteed.
However on a multi-core system where the read/write operations cannot be guaranteed, a synchronization method has to be implemented that allows the contents of the shared memory to by synchronized across the whole system. This synchronisation method is the memory barrier.
With the above example, the memory barrier implementation would be :
thread 1: a = 1; memory_barrier; b = 1; thread 2: while (b != 1); memory_barrier; assert(a==1);
In the above example, the first memory barrier makes sure that the variables a and b are written to in the specified order. The second memory barrier makes sure that the read operations are done in the correct order (the value of variable b is read before the value of variable a).
Two forms of memory barrier are supported by the Symbian platform:
One that will only allow any subsequent memory access if all the previous memory access operations have been observed.
This memory barrier does not guarantee the order of completion of the memory requests.
This equates to the ARM DMB (Data Memory Barrier) instruction.
This is implemented via the __e32_memory_barrier() function.
One that ensures that all previous memory and I/O access operations are complete before any new access instructions can be executed.
This equates to the ARM DSB (Data Synchronisation Barrier) instruction. The difference between this form of memory barrier and the previous one, is that all of the cache operations will have been completed before the memory barrier instruction completes and that no instruction can be executed until the memory barrier instruction has been completed.
This is implemented via the ___e32_io_completion_barrier() function.
Memory barriers are used in implementing lockless algorithms, which perform shared memory operations without using locks. They are used in areas where performance is a prime requirement.
It is unlikely that memory barriers would be used by anyone other than device drivers (especially the __e32_io_completion_barrier() function). It is also unlikely that these functions would be used on their own. Instead they are most likely to be called via one of the atomic operation functions. An example of their use is :
/* Make sure change to iTail is not observed before the trace data reads which preceded the call to this function. */
__e32_memory_barrier();
buffer->iTail += iLastGetDataSize;
Copyright ©2010 Nokia Corporation and/or its subsidiary(-ies).
All rights
reserved. Unless otherwise stated, these materials are provided under the terms of the Eclipse Public License
v1.0.