Thread Synchronisation
Kernel-side techniques to protect critical regions in code or to allow safe access to shared data.
Kernel-side code can use a number of techniques to perform thread synchronisation, to protect critical regions within threads or to ensure that shared data can be safely read or modified.
Mutexes
A mutex (mutual exclusion) is a mechanism to prevent more than one thread from executing a section of code concurrently. The most common use is to synchronise access to data shared between two or more threads.
There are two types of mutex: the fast mutex, and a more general heavyweight mutex - the Symbian platform mutex. Which one you use depends on the needs of your code and the context in which it runs.
A fast mutex is the fundamental way of allowing mutual exclusion between nanokernel threads. Remember that a Symbian platform thread, and a thread in a personality layer are also nanokernel threads.
A fast mutex is represented by a NFastMutex object. It is designed to be as fast as possible, especially in the case where there is no contention, and is also designed to occupy as little RAM as possible. A fast mutex is intended to protect short critical sections of code
A fast mutex is, be definition, fast and the price to be paid is that there are a few rules that must be obeyed:
a thread can only hold one fast mutex at a time, i.e. a thread cannot wait on a fast mutex if it already holds another fast mutex
a thread cannot wait on the same fast mutex more than once
a thread must not block or exit while holding a fast mutex because the thread is in an implied critical section.
In the moving memory model, the user address space is not guaranteed to be consistent while a kernel thread holds a fast mutex.
Typically you declare a fast mutex in a class declaration, for example:
class DImpSysTest : public DLogicalChannelBase { ... public: ... NFastMutex iMutex; ... };
When you want to get hold of the fast mutex, i.e. when you are about to enter a section of code that no other thread is executing concurrently, you wait on that fast mutex. If no other thread has the mutex, then your thread gets the mutex, and control flows into your critical code. On exiting the section of code, you signal the fast mutex, which relinquishes it.
If, on the other hand, another thread already has the fast mutex, then your thread blocks, and only resumes when the other thread exits the code section by signalling the fast mutex.
Getting and relinquishing the mutex is done using the Wait() and Signal() functions of the NFastMutex class. However, you will normally use the nanokernel functions:
respectively, passing a pointer to your NFastMutex object.
The kernel lock must be held when NFastMutex::Wait() and NFastMutex::Signal() are called. NKern::FMWait() and NKern::FMSignal() do this for you. They make sure that the kernel lock is on while NFastMutex::Wait() and NFastMutex::Signal() are called by wrapping them in a pair of NKern::Lock() and NKern::Unlock() calls.
Although this sounds like you will be blocking while holding the kernel lock, in reality you do not because the thread is not blocked until after the kernel lock is released.
Be aware however that there may be situations where you already have the kernel lock, or in the case of IDFCs, you do not need to acquire it as no preemption can occur. In these cases, you just call NFastMutex::Wait() and NFastMutex::Signal().
The following diagram illustrates the general principle:
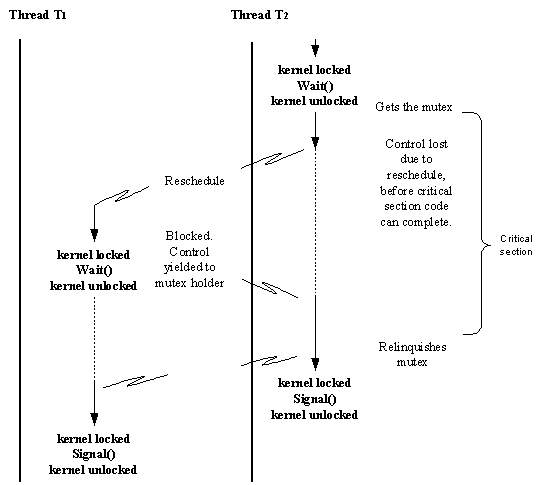
There are a number of assumptions here, one of which is that the priorities are such that thread T1 does not run until a reschedule occurs, after T2 has been interrupted.
Example using NFastmutex to protect a critical region
The file ...\f32test\nkern\d_implicit.cpp is a device driver that contains 3 threads and 3 separate sub-tests. The third test, identified as ETestDummy, shows how to protect a critical region using a nanokernel fast mutex.
The mutex itself is declared in the channel class:
class DImpSysTest : public DLogicalChannelBase { ... public: ... NFastMutex iMutex; ... };
The function Start() takes an argument that sets the test number. This function initialises some test variables, creates three threads, and also initialises the mutex:
TInt DImpSysTest::Start(TInt aTest) { ... new (&iMutex) NFastMutex; ... }
The overloaded new operator is called with the existing mutex as its argument, with the side effect of calling the constructor to initialise the mutex. There is also a corresponding Stop() function to kill the threads and return the results to the caller.
Look at the test case for iTestNum == ETestDummy, where thread 1 and thread 3 use the mutex as if sharing a critical resource.
void DImpSysTest::Thread1(TAny* aPtr) { DImpSysTest& d=*(DImpSysTest*)aPtr; ... FOREVER { NKern::FMWait(&d.iMutex); // this is a critical region protected by d.iMutex NKern::FMSignal(&d.iMutex); ... } }
void DImpSysTest::Thread3(TAny* aPtr) { DImpSysTest& d=*(DImpSysTest*)aPtr; ... if (d.iTestNum==RImpSysTest::ETestPriority) { ... } else if (d.iTestNum==RImpSysTest::ETestDummy) { FOREVER { ... if (x<85) { ... } else { NKern::FMWait(&d.iMutex); // this is a critical region protected by d.iMutex NKern::FMSignal(&d.iMutex); } } } }
Each thread takes a pointer to the channel object as an argument, this is the aPtr value passed to both Thread1() and Thread3() and each thread dereferences it to find the mutex. The important point is that there is only one mutex object, which is accessed by all interested threads.
Before entering the critical region, the threads call NKern::FMWait() to gain ownership of the mutex. Before leaving the critical region, they call NKern::FMSignal() to relinquish ownership.
The Symbian platform mutex provides mutual exclusion between Symbian platform threads without the restrictions imposed by the fast mutex.
The Symbian platform mutex is represented by a DMutex object.
Operations on a DMutex are more complicated, and therefore slower, than those on a NFastMutex. However, a DMutex gives you the following:
it is possible to wait on a Symbian platform mutex multiple times, provided it is signalled the exact same number of times
It is possible to hold several Symbian platform mutexes simultaneously, although care is needed to avoid deadlock situations
A thread can block while holding a Symbian platform mutex
A Symbian platform mutex provides priority inheritance, although there is a limit on the number of threads that can wait on any DMutex (currently this is 10).
When a Symbian platform mutex is created it is given an 'order' value. This is a deadlock prevention mechanism, although it is used only in debug builds. When waiting on a mutex the system checks that the order value is less than the order value of any mutex that the thread is already waiting on.
In general, most code written for device drivers should use values which are greater than any used by the kernel itself. There are 8 constants defined in kernel.h that are available for this purpose: KMutexOrdGeneral0 through KMutexOrdGeneral7.
The kernel faults with “Mutex Ordering Violation” if you try to wait on a mutex that violates the ordering rules.
Note: the only time when these values would not be suitable is when the kernel calls back into non-kernel code while a mutex is already held by the kernel. This occurs in only two cases:
The debug event handler callback
The various timer classes like TTimer. This should not be an issue because device drivers should use the NTimer class which does not callback while DMutexes are held.
Typically you declare the mutex in a class declaration, for example:
class DCrashHandler : public DKernelEventHandler { ... private: DMutex* iHandlerMutex; ... };
You do not create a DMutex object directly; instead you use the kernel function Kern::MutexCreate(). You pass a DMutex* type to the kernel function, which creates the DMutex object and returns a reference to it through the DMutex pointer.
Getting and relinquishing the mutex is done using the kernel functions:
respectively, passing a reference to the DMutex object created earlier. Note that although you pass a DMutex object around, the member functions and member data of the class are considered as internal to Symbian platform. However, you can call Open() and Close() on DMutex as they are members of the base class DObject.
Example using DMutex to protect critical regions
This example code fragment uses two DMutex objects to protect a critical region of code in a device driver. It implements a minimal debug agent in a device driver. When a channel is opened to the device driver, the DoCreate() function creates a crash handler (in 2 phases). The DCrashHandler class contains two DMutex objects:
class DCrashHandler : public DKernelEventHandler { ... private: DMutex* iHandlerMutex; // serialise access to crash handler ... DMutex* iDataMutex; // serialise access to following members ... };
The two DMutex objects are created in the second phase of the crash handler creation, i.e. when the member function DCrashHandler::Create() is called. Here's the code:
TInt DCrashHandler::Create(DLogicalDevice* aDevice) { TInt r; ... r = Kern::MutexCreate(iHandlerMutex, KHandlerMutexName, KMutexOrdDebug); ... r = Kern::MutexCreate(iDataMutex, KDataMutexName, KMutexOrdDebug-1); ... }
The names of the mutexes are passed as the literal descriptors: KHandlerMutexName and KDataMutexName, and have the values CtHandlerMutex and CtDataMutex respectively.
Notice that the data mutex has an order value less than the handler mutex. This guards against deadlock - we are asking the kernel to check that any thread waits on the handler mutex before it waits on the data mutex.
When a thread panics, or an exception occurs, program control eventually reaches DCrashHandler::HandleCrash(). The device driver is derived from DLogicalChannelBase, and the current thread is the one that crashed and this is a Symbian platform thread, which means that it can wait on a DMutex. In fact, it waits on two mutexes, and does so in the order mentioned above. The mutexes are signalled further on in the same function.
void DCrashHandler::HandleCrash(TAny* aContext) { ... // Ensure that, at any time, at most one thread executes the // following code. This simplifies user-side API. Kern::MutexWait(*iHandlerMutex); ... Kern::MutexWait(*iDataMutex); ... // access crash handler data <------------------------------------- ... Kern::MutexSignal(*iDataMutex); ... Kern::MutexSignal(*iHandlerMutex); }
iHandlerMutex ensures that only one thread at a time uses the above code. iDataMutex protects a smaller critical region where the crash handler’s data is accessed. This data is also protected by iDataMutex in the DCrashHandler::Trap() function.
void DCrashHandler::Trap(TRequestStatus* aRs, TAny* aCrashInfo) { ... Kern::MutexWait(*iDataMutex); ... // access crash handler data <------------------------------------- ... Kern::MutexSignal(*iDataMutex); ... }
A DMutex is a reference counting object, and is derived from DObject. This means that once you have finished with it, you must call Close() on it to reduce the number of open references.
In this example, both DMutex objects are closed in the DCrashHandler destructor:
DCrashHandler::~DCrashHandler() { ... if (iDataMutex) { iDataMutex->Close(NULL); } if (iHandlerMutex) { iHandlerMutex->Close(NULL); } ... }
Semaphores
A semaphore is synchronisation primitive that you can use:
to signal one thread from another thread
to signal a thread from an Interrupt Service Routine using an IDFC.
In EKA2, there are two types of semaphore: the fast semaphore, and a more general semaphore - the Symbian platform semaphore. Which one you use depends on the needs of your code and the context in which it is runs.
A fast semaphore is a fast lightweight mechanism that a thread can use to wait for events. It provides a way of posting events to a single thread because the semaphore can keep count of the number of events posted.
A fast semaphore is represented by a NFastSemaphore object, and this is implemented by the nanokernel. Remember that a Symbian platform thread, and a thread in a personality layer are also nanokernel threads.
Because of its lightweight structure, only the owning thread is allowed to wait on it.
Typically you declare a fast semaphore in a class declaration, for example:
class DCrashHandler : public DKernelEventHandler { ... private: NFastSemaphore iSem; ... };
You need to initialise the NFastSemaphore by:
constructing the semaphore
setting the thread that owns the semaphore, i.e. the thread that will be allowed to wait in it.
The semaphore is initialised when its constructor is called. However, setting the owning thread requires explicit code. For example, the following code fragment is typical and sets the owning thread to be the current thread:
iSem.iOwningThread = (NThreadBase*)NKern::CurrentThread();
Waiting and signalling the fast semaphore is done by using the Wait() and Signal() functions of the NFastSemaphore class. However, you will normally use the nanokernel functions:
respectively, passing a pointer to your NFastSemaphore object.
The kernel lock must be held when NFastSemaphore::Wait() and NFastSemaphore::Signal() are called. NKern::FSWait() and NKern::FSSignal() do this for you. They make sure that the kernel lock is on while NFastSemaphore::Wait() and NFastSemaphore::Signal() are called by wrapping them in a pair of NKern::Lock() and NKern::Unlock() calls.
Although this sounds like you will be blocking while holding the kernel lock, in reality you do not because the thread is not blocked until after the kernel lock is released.
Be aware however that there may be situations where you already have the kernel lock, or in the case of IDFCs, you do not need to acquire it as no preemption can occur. In these cases, you just call NFastSemaphore::Wait() and NFastSemaphore::Signal().
You can use use a fast semaphore to block a thread until an interrupt occurs, but you cannot signal the semaphore directly from the interrupt service routine (ISR) that services that interrupt; instead, you must queue an IDFC, and signal from there.
Example using NFastSemaphore and the NKern functions
This is an example that synchronises threads using the NFastSemaphore class, and is part of code that implements a minimal debug agent in a device driver. The full code for this can be found in ...\e32utils\d_exc\minkda.cpp.
When a channel is opened, the DoCreate() function creates a crash handler (in 2 phases).This is a DCrashHandler object, and importantly, contains a NFastSemaphore.
class DCrashHandler : public DKernelEventHandler { ... private: NFastSemaphore iSuspendSem; // for suspending crashed thread ... };
When a thread panics, or an exception occurs, program control eventually reaches DCrashHandler::HandleCrash(). It is in this function that the owning thread is set – to the current nanokernel thread (i.e. the one that crashed). This is the only thread allowed to wait on the semaphore. The wait is just a few lines further down in the same function:
void DCrashHandler::HandleCrash(TAny* aContext) { DThread* pC = &Kern::CurrentThread(); ... if (iTrapRq != NULL) { iCrashedThread = pC; iSuspendSem.iOwningThread = &(iCrashedThread->iNThread); ... } ... if (iCrashedThread) { ... NKern::FSWait(&(iSuspendSem)); // Waits on the semaphore ... } ... }
At a later time, the debugger calls the driver’s Request() function with either the ECancelTrap or EKillCrashedThread parameters. One or other of the corresponding functions is called; each function is implemented to signal the semaphore.
void DCrashHandler::CancelTrap() { ... if (iCrashedThread != NULL) { NKern::FSSignal(&(iSuspendSem)); } ... }
void DCrashHandler::KillCrashedThread() { ... NKern::FSSignal(&iSuspendSem); }
Example using the NFastSemaphore::Signal() function
This is an example code fragment taken from ...\e32test\misc\d_rndtim.cpp.
This a device driver that uses a timer. The driver's logical channel can start the timer, and it can wait for the timer to expire. The expiry of the timer results in an interrupt; this results in a call to an ISR that schedules an IDFC, which, in turn, signals the driver's logical channel.
Because the kernel is implicitly locked when the IDFC runs, there is no need to explicitly lock the kernel, and NFastSemaphore::Signal() can be called instead of NKern::FSSignal().
The relevant part of the driver's logical channel class is:
class DRndTim : public DLogicalChannelBase { ... public: NFastSemaphore iSem; ... };
The semaphore's owning thread is set in the logical channel's constructor. Note that the constructor is called in the context of the client thread, and it is this thread that is the owner of the semaphore. This must also be the thread that waits for the semaphore, which it does when at some later time it sends an EControlWait request to the device driver to wait for the timer to expire.
DRndTim::DRndTim() { iThread=&Kern::CurrentThread(); iThread->Open(); iSem.iOwningThread = &iThread->iNThread; ... }
The following code shows the implementation of this wait. Note that it assumes that the timer has already been started, which we have not shown here.
The wait is initiated using the NKern::FSWait() function as the kernel must be locked when the wait operation is done on the NFastSemaphore.
TInt DRndTim::Request(TInt aFunction, TAny* a1, TAny* a2) { TInt r = KErrNotSupported; switch (aFunction) { case RRndTim::EControlWait: NKern::FSWait(&iSem); r = KErrNone; break; ... } ... }
When the timer expires, the ISR runs, and this schedules the IDFC, which in turn signals the client thread. The following code is the IDFC implementation.
void DRndTim::IDfcFn(TAny* aPtr) { DRndTim* d = (DRndTim*)aPtr; d->iSem.Signal(); }
Note that this calls NFastSemaphore::Signal() rather that NKern::FSSignal() because IDFCs are called with the kernel locked.
The Symbian platform semaphore
Symbian platform semaphores are standard counting semaphores that can be used by one or more Symbian platform threads. The most common use of semaphores is to synchronise processing between threads, i.e. to force a thread to wait until some processing is complete in one or more other threads or until one or more events have occurred.
The Symbian platform semaphore is represented by a DSemaphore object.
A Symbian platform semaphore is based on the value of a count, which the DSemaphore object maintains. The value of the count indicates whether there are any threads waiting on it. The general behaviour is:
if the count is positive or zero, then there are no threads waiting
if the count is negative, the magnitude of the value is the number of threads that are waiting on it.
There are two basic operations on semaphores:
WAIT - this decrements the count atomically. If the count remains non-negative the calling thread continues to run; if the count becomes negative the calling thread is blocked.
SIGNAL - this increments the count atomically. If the count was originally negative the next highest priority waiting thread is released.
Waiting threads are released in descending order of priority. Note however that threads that are explicitly suspended as well as waiting on a semaphore, are not kept on the semaphore wait queue; instead they are kept on a separate suspended queue. Such threads are not regarded as waiting for the semaphore; this means that if the semaphore is signalled, they will not be released, and the semaphore count will just increase and may become positive.
Symbian platform semaphore operations are protected by the system lock fast mutex rather than by locking the kernel. To guarantee this, semaphore operations are done through kernel functions.
Although somewhat artificial, and not based on real code, the following diagram nevertheless shows the basic idea behind Symbian platform semaphores.
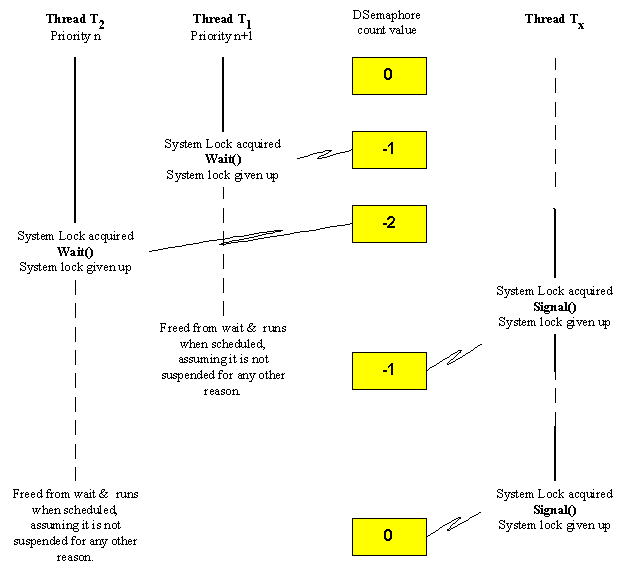
There are a few rules about the use of Symbian platform semaphores:
Only Symbian platform threads are allowed to use Symbian platform semaphores
An IDFC is not allowed to signal a Symbian platform semaphore.
Typically you declare the Symbian platform semaphore in a class declaration, for example:
class X { ... private: DSemaphore* iSemaphore; ... };
You cannot create a DSemaphore object directly; instead you must use the kernel function Kern::SemaphoreCreate(). You pass a DSemaphore* type to the kernel function, which creates the DSemaphore object and returns a reference to it through the DSemaphore pointer.
Waiting on the semaphore and signalling the semaphore are done using the kernel functions:
respectively, passing a reference to the DSemaphore object created earlier. Note that although you pass a DSemaphore object around, the member functions and member data of the class are considered as internal to Symbian platform, and indeed the member functions are not exported and are not accessible except to the kernel itself. However, you can call Open() and Close() on DSemaphore as they are members of the base class DObject.
Thread critical section
Putting a thread into a thread critical section prevents it being killed or panicked. Any kill or panic request is deferred until the thread leaves the critical section.
A thread critical section is used to protect a section of code that is changing a global data structure or some other global resource. Killing a thread that is in the middle of manipulating such a global data structure might leave it in a corrupt state, or marked is being "in use".
A thread critical section only applies to code that is running on the kernel side but in the context of a user thread. Only user threads can be terminated or panicked by another thread.
In practice, a thread critical section only applies to code implementing a DLogicalChannelBase::Request() function or a HAL function handler.
Enter a thread critical section by calling: NKern::ThreadEnterCS().
Exit a thread critical section by calling: NKern::ThreadLeaveCS().
Note:
it is important that you only hold a thread critical section for the absolute minimum amount of time it takes to access and change the resource.
you do not need to be in a critical section to hold a fast mutex because a thread holding a fast mutex is implicitly in a critical section.
There are a large number of examples scattered throughout Symbian platform source code.
Atomic operations
There are a number of functions provided by the nanokernel that allow you to do atomic operations, and may be useful when synchronising processing or ensuring that data is safely read and/or updated.
This is a list of the functions that are available. The function descriptions provide sufficient information for their use.
The system lock
The system lock is a specific fast mutex that only provides exclusion against other threads acquiring the same fast mutex. Setting, and acquiring the system lock means that a thread enters an implied critical section.
The major items protected by the system lock are:
DThread member data related to thread priority and status.
the consistency of the memory map. On the kernel side, the state of user side memory or the mapping of a process is not guaranteed unless one or other of the following conditions is true:
the lifetime of DObject type objects and references to them, including handle translation in Exec dispatch.
Note that the system lock is different from the kernel lock; the kernel lock protects against any rescheduling. When the system lock is set, the calling thread can still be preempted, even in the locked section.
The system lock is set by a call to NKern::LockSystem().
The system lock is unset by a call to NKern::UnlockSystem()
Only use the system lock when you access a kernel resource that is protected by the system lock. Generally you will not access these directly but will use a kernel function, and the preconditions will tell you whether you need to hold the system lock.
The kernel lock
The kernel lock disables the scheduler so that the currently running thread cannot be pre-empted. It also prevent IDFCs from running. If the kernel lock is not set, then IDFCs can run immediately after ISRs
Its main purpose is to prevent code from being reentered and corrupting important global structures such as the thread-ready list.
The kernel lock is set by a call to NKern::Lock().
The kernel lock is unset by a call to NKern::Unlock()
ALMOST NEVER.
The kernel exports this primarily for use by personality layers, which need to modify the thread-ready list. In general, you should use a fast mutex for thread synchronisation.
Disabling interrupts
This is the most drastic form of synchronisation. With interrupts disabled, timeslicing cannot occur. If interrupts are disabled for any length of time, the responsiveness of the whole system may be threatened, and real time guarantees may be invalidated.
How to use
There are three functions supplied by the nanokernel involved in disabling and enabling interrupts.
When to use
NEVER.
Unless there is absolutely no other suitable technique. You would probably only use this to protect some data that is shared between an interrupt service routine and a thread (or a DFC). Nevertheless, you may find that atomic operations are more suitable.
Copyright ©2010 Nokia Corporation and/or its subsidiary(-ies).
All rights
reserved. Unless otherwise stated, these materials are provided under the terms of the Eclipse Public License
v1.0.