Shared Chunks
A shared chunk is a mechanism that kernel-side code uses to share memory buffers safely with user-side code.
A shared chunk is a mechanism that kernel-side code can use to share memory buffers safely with user-side code. This topic describes this concept, and explains how to use the shared chunk APIs.
You may find it useful to refer to the general sections : Device Driver Concepts and Device Driver Framework.
What are shared chunks?
A shared chunk is a mechanism that kernel-side code uses to share memory buffers safely with user-side code. References to kernel-side code always mean device driver code.
The main points to note about shared chunks are:
They can be created and destroyed only by device drivers. It is typical behaviour for user-side code, which in this context we refer to as the client of the device driver, to pass a request to the device driver for a handle to a shared chunk. This causes the device driver to open a handle to the chunk and return the handle value to the client. Successful handle creation also causes the chunk's memory to be mapped into the address space of the process to which the client's thread belongs. Note, however, that the driver dictates when the chunk needs to be created, and when memory needs to be committed.
Like all kernel-side objects, a shared chunk is reference counted. This means that it remains in existence for as long as the reference count is greater than zero. Once all opened references to the shared chunk have been closed, regardless of whether the references are user-side or kernel-side, it is destroyed.
User-side code that has gained access to a shared chunk from one device driver can pass this to a second device driver. The second device driver must open the chunk before it can be used.
More than one user-side application can access the data in a shared chunk. A handle to a shared chunk can be passed from one process to another using standard handle passing mechanisms. In practice, handles are almost always passed in a client-server context via inter process communication (IPC).
Processes that share the data inside a chunk should communicate the location of that data as an offset from the start of the chunk, and not as an absolute address. The shared chunk may appear at different addresses in the address spaces of different user processes.
Creating a shared chunk
A shared chunk can be created only by code running on the kernel-side. This means that it is the device driver's responsibility to create a chunk that is to be shared by user-side code. There is no user-side API that allows user-side code to create shared chunks.
The device driver creates a shared chunk using the Kern::ChunkCreate() function. It passes to this function a TChunkCreateInfo object containing the required attributes for that chunk. The most important attribute is the TChunkCreateInfo::ESharedKernelMultiple attribute that states that a shared chunk is to be created.
Chunks are reference counted kernel objects. When the chunk is created, the reference count is set to one.
Opening a handle to the shared chunk for user-side access
Before user-side code can access the memory in a shared chunk, the device driver must create a handle to the chunk and then pass the value back to the user-side. It does this by calling the Kern::MakeHandleAndOpen() function, passing the information:
a pointer to the user-side code's thread (or NULL if referring to the current thread)
a pointer to the shared chunk
Typically, the device driver does this in response to a request from the user-side. Kern::MakeHandleAndOpen() also maps the chunk's memory into the address space of the user-side code's thread.
If the creation of the handle is successful, the device driver returns the handle value back to the user-side. The user-side code then assigns the value to an RChunk object using one of RChunk's base class functions:
The user-side code uses RHandleBase::SetReturnedHandle() if the device driver returns either a positive handle value or a negative error code. A negative error code means that handle creation has failed.
Opening a handle to a shared chunk increases the reference count by one.
See Example: Opening a handle to the shared chunk for user-side access.
Closing a handle
After it has been opened, a device driver may need to perform further operations before the handle can be returned to the user-side. If these operations fail, the device driver code may want to unwind the processing it has done, including discarding the handle it has just created. It does this using the function Kern::CloseHandle().
This reverses the operation performed by Kern::MakeHandleAndOpen().
Closing and destroying a shared chunk
There is no explicit method for deleting or destroying shared chunks. Instead, because chunks are reference counted kernel objects, a device driver can use the function Kern::ChunkClose(). This function decrements a chunk's access count, and, if the count reaches zero, the chunk is scheduled for destruction.
The chunk is not be destroyed immediately. Instead it is done asynchronously. If the device driver needs to know when the chunk has been destroyed, it must specify a DFC (Deferred Function Call) at the time the chunk is created. The device driver specifies the DFC through the TChunkCreateInfo::iDestroyedDfc member. The DFC is queued to run only when the chunk has finally been destroyed. At this point it is guaranteed that the memory mapped by the chunk can no longer be accessed by any code. This is useful in cases where chunks are used to map I/O devices or other special memory, and the program managing these needs to know when they are free to be reused.
Note: For each call to Kern::ChunkCreate() and Kern::OpenSharedChunk() there should be exactly one call to Kern::ChunkClose(). Calling Close() too few times can cause memory leaks. Calling Close() too many times can cause the chunk to be destroyed while a program is still trying to access the memory, which causes an application panic for user code and a system crash for kernel code.
Committing memory
After a shared chunk has been created it owns a region of contiguous virtual addresses. This region is empty, which means that it is not mapped to any physical RAM or memory mapped I/O devices.
Before the chunk can be used, the virtual memory must be mapped to real physical memory. This is known as committing memory.
Committing RAM from the system free memory pool
You can commit RAM taken from the system free memory pool using the following ways:
by committing an arbitrary set of pages. Use the function Kern::ChunkCommit().
by committing a set of pages with physically contiguous addresses. Use the function Kern::ChunkCommitContiguous().
Committing specified physical addresses
You can commit specific physical addresses, but only if you set the data member TChunkCreateInfo::iOwnsMemory to EFalse when you create the shared chunk - see Creating a shared chunk.
You can use the following ways to do this:
by committing a region of contiguous addresses. Use the function Kern::ChunkCommitPhysical() with the signature:
TInt Kern::ChunkCommitPhysical(DChunk*, TInt, TInt, TUint32)
by committing an arbitrary set of physical pages. Use the function Kern::ChunkCommitPhysical() with the signature:
TInt Kern::ChunkCommitPhysical(DChunk*, TInt, TInt, const TUint32*)
Note: the same physical memory can be committed to two different RChunk s or shared chunks at the same time, where each RChunk has a different owner, as long as your turn OFF the caches.
Passing data from user-side code to another device driver
User-side code that has access to a shared chunk from one device driver may want to use this when it communicates with another device driver. To enable this, the second device driver needs to gain access to the chunk and the addresses used by the memory it represents.
The second driver must open a handle on the shared chunk before any of its code can safely access the memory represented by that chunk. Once it has done this, the reference counted nature of chunks means that the chunk, and the memory it represents, remains accessible until the chunk is closed.
The general pattern is:
the first device driver creates the shared chunk.
the user-side gets the handle value from the first device driver and calls SetHandle() or SetReturnedHandle() on an RChunk object [the functions are members of RChunk's base class RHandleBase (see RHandleBase::SetHandle() and RHandleBase::SetReturnedHandle()].
See Opening a handle to the shared chunk for user-side access.
the user-side passes the handle value to the second device driver. This value is obtained by calling Handle() on the RChunk object. [the function is a member of RChunk's base class RHandleBase (see RHandleBase::Handle()].
the second device driver calls the variant of Kern::OpenSharedChunk() with the signature:
DChunk* Kern::OpenSharedChunk(DThread*,TInt,TBool)
to open a handle to the shared chunk.
Note: there are situations where the second device driver cannot use this variant of Kern::OpenSharedChunk() because:
The user-side application may have obtained data by using a library API that uses shared chunks internally, but which only presents a descriptor based API to the user application. For example, an image conversion library may perform JPEG decoding using a DSP, which puts its output into a shared chunk, but that library supplies the user application with only a descriptor for the decoded data, not a chunk handle.
The communication channel between the user-side application and the device driver supports descriptor based APIs only, and does not have an API specifically for shared chunks. The API items presented by the File Server are an example of this situation.
The second device driver will only have the address and size of the data (usually a descriptor). If the driver needs to optimise the case where it knows that this data resides in a shared chunk, it can use the variant of Kern::OpenSharedChunk() with the signature:
DChunk* Kern::OpenSharedChunk(DThread*,const TAny*,TBool,TInt&)
to speculatively open the chunk.
Getting the virtual address of data in a shared chunk
Before device driver code can access a shared chunk that is has opened, it must get the address of the data within it. Typically, user-side code will pass offset and size values to the driver. The driver converts this information into an address, using the function Kern::ChunkAddress().
Getting the physical address of data in a shared chunk
Device driver code can get the physical address of a region within a shared chunk from the offset into the chunk and a size value. This is useful for DMA or any other task that needs a physical address. Use the function Kern::ChunkPhysicalAddress() to do this.
Getting chunk attributes and checking for uncommitted memory
As a shared chunk may contain uncommitted regions of memory (gaps), it is important that these gaps are detected. Any attempt to access a bad address causes an exception. You can use the function Kern::ChunkPhysicalAddress() to check for uncommitted regions of memory.
Passing data between user-side code
User-side code can access data in a shared chunk once it has opened a handle on that chunk. Handles can be passed between user processes using the various handle passing functions. This most common scenario is via client-server Inter Process Communication (IPC).
Passing a handle from client to server
The client passes the handle to the shared chunk as one of the four arguments in a TIpcArgs object. The server opens this using the RChunk::Open() variant with the signature:
RChunk::Open(RMessagePtr2 aMessage,TInt aParam,TBool isReadOnly, TOwnerType aType)
Passing a handle from server to client
The server completes the client message using the chunk handle:
RMessagePtr2::Complete(RHandleBase aHandle)
The client then assigns the returned handle value to an RChunk by calling:
RChunk::SetReturnedHandle(TInt aHandleOrError)
Note:
Processes that share data within shared chunks must specify the address of that data as an offset from the start of the chunk, and not as an absolute address. This is because the chunk may appear at different addresses in the address spaces of different user processes.
Once a chunk is no longer needed for data sharing, user applications should close the handle they have on it. If they do not, the memory mapped by the chunk can never be freed.
See Using Client/Server.
Direct peripheral access to shared chunks
When DMA or any other hardware device accesses the physical memory represented by a shared chunk, the contents of CPU memory cache(s) must be synchronised with that memory. Use these functions for this purpose:
Note: both these functions take a TUint32 type parameter, identified in the function signatures as TUint32 aMapAttr. This is the same TUint32 value set on return from calls to either Kern::ChunkPhysicalAddress() or Kern::ChunkCreate().
Example code
This section contains code snippets that show shared chunks in use. Most of the code is intended to be part of a device driver. A few snippets show user-side code and the interaction with device driver code.
Example: Creating a shared chunk
This code snippet shows how a device driver creates a shared chunk. The class DMyDevice has been given responsibility for creating the chunk:
/** The device or other object making use of shared chunks */ class DMyDevice { ... TInt CreateChunk(); void CloseChunk(); private: void ChunkDestroyed(); private: TBool iMemoryInUse; DChunk* iChunk TUint32 iChunkMapAttr; TLinAddr iChunkKernelAddr; ... }
/* Address and size of our device's memory */ const TPhysAddr KMyDeviceAddress = 0xc1000000; // Physical address const TInt KMyDeviceMemorySize = 0x10000; /** Create a chunk which maps our device's memory */ TInt DMyDevice::CreateChunk() { // Check if our device's memory is already in use if(iMemoryInUse) { // Wait for short while (200ms) in case chunk is being deleted NKern::Sleep(NKern::TimerTicks(200)); // Check again if(iMemoryInUse) { // Another part of the system is probably still using our memory, so... return KErrInUse; } } // Enter critical section so we can't die and leak the objects we are creating // I.e. the TChunkCleanup and DChunk (Shared Chunk) NKern::ThreadEnterCS(); // Create chunk cleanup object TChunkCleanup* cleanup = new iChunkCleanup(this); if(!cleanup) { NKern::ThreadLeaveCS(); return KErrNoMemory; } // Create the chunk TChunkCreateInfo info; info.iType = TChunkCreateInfo::ESharedKernelMultiple; info.iMaxSize = KMyDeviceMemorySize; info.iMapAttr = EMapAttrFullyBlocking; // No caching info.iOwnsMemory = EFalse; // We'll be using our own devices memory info.iDestroyedDfc = cleanup; DChunk* chunk; TInt r = Kern::ChunkCreate(info, chunk, iChunkKernelAddr, iChunkMapAttr); if(r!=KErrNone) { delete cleanup; NKern::ThreadLeaveCS(); return r; } // Map our device's memory into the chunk (at offset 0) r = Kern::ChunkCommitPhysical(chunk,0,KMyDeviceMemorySize,KMyDeviceAddress); if(r!=KErrNone) { // Commit failed so tidy-up... // We, can't delete 'cleanup' because it is now owned by the chunk and will // get run when the chunk is destroyed. Instead, we have to Cancel it, which // prevents it from doing anything when it does run. cleanup->Cancel() // Close chunk, which will then get deleted at some point Kern::ChunkClose(chunk); } else { // Commit succeeded so flag memory in use and store chunk pointer iMemoryInUse = ETrue; iChunk = chunk; } // Can leave critical section now that we have saved pointers to created objects NKern::ThreadLeaveCS(); return r; } /** Close the chunk which maps our device's memory */ TInt DMyDevice::CloseChunk() { // Enter critical section so we can't die whilst owning the chunk pointer NKern::ThreadEnterCS(); // Atomically get pointer to our chunk and NULL the iChunk member DChunk* chunk = (DChunk*)NKern::SafeSwap(NULL,(TAny*&)iChunk); // Close chunk if(chunk) Kern::CloseChunk(chunk); // Can leave critical section now NKern::ThreadLeaveCS(); }
Implementation notes
a TChunkCreateInfo object is created, populated and passed to Kern::ChunkCreate(). This is information that Symbian platform needs to create the chunk. To create a shared chunk, TChunkCreateInfo::iType must be set to TChunkCreateInfo::ESharedKernelMultiple.
If the device architecture allowed the device driver function DMyDevice::CreateChunk() to be called in a re-entrant manner, you would need to protect this code using a mutex. Such a situation might arise when a logical channel is shared between two threads, or two logical channels are created on the same device. There may also be other cases where a mutex is needed.
See also:
The line:
info.iDestroyedDfc = cleanup;
in the function DMyDevice::CreateChunk() and code following the comment
// Create chunk cleanup object
sets the DFC that runs when the shared chunk is finally closed. See Example: using a DFC to notify destruction of chunk for the DFC code itself.
Example: Opening a handle to the shared chunk for user-side access
These code snippets show user-side code making a request to a device driver to open handles on two shared chunks.
The code snippets assume that the chunks have already been created.
User-side
The user-side interface to a device driver is always a class derived from RBusLogicalChannel, and is provided by the device driver. Here, this is the RMyDevice class. In real code, the class would offer much more functionality, but only the relevant function members and data members are shown:
/** Client (user-side) interface to the device driver. */ class RMyDevice : public RBusLogicalChannel { ... public: TInt OpenIoChunks(RChunk& aInputChunk,RChunk& aOutputChunk); ... private: /** Structure to hold information about the i/o buffers */ class TIoChunkInfo { public: TInt iInputChunkHandle; TInt iOutputChunkHandle; }; // Kernel-side channel class is a friend... friend class DMyDeviceChannel; ... };
You call the function OpenIoChunks() to:
issue a request to the driver to create handles to two chunks
get handles to those shared chunks so that they can be accessed by user-side code.
TInt RMyDevice::OpenIoChunks(RChunk& aInputChunk,RChunk& aOutputChunk) { // Send request to driver to create chunk handles. TIoChunkInfo info; TInt r=DoControl(EOpenIoChunks,(TAny*)&info); // Set the handles for the chunks aInputChunk.SetHandle(info.iInputChunkHandle); aOutputChunk.SetHandle(info.iOutputChunkHandle); return r; }
Implementation notes
The request is passed to the driver as a synchronous call; it calls the base class function RBusLogicalChannel::DoControl(). This means that the call does not return until the driver has created (or failed to create) the handles to the shared chunks. The call is synchronous because the creation of the handles does not depend on the hardware controlled by the driver, so there should be minimal delay in its execution.
The driver returns the handle numbers in the TIoChunkInfo object; specifically in its iInputChunkHandle and iOutputChunkHandle data members.
To access the shared chunks, user-side code needs handles to them. Handles to chunks are RChunk objects.
The final step is to set the returned handle numbers into the RChunk objects by calling SetHandle(). This function is provided by RChunk's base class RHandleBase.
See handles for background information.
In this example the return value from RBusLogicalChannel::DoControl() is not checked. In practice you need to do so.
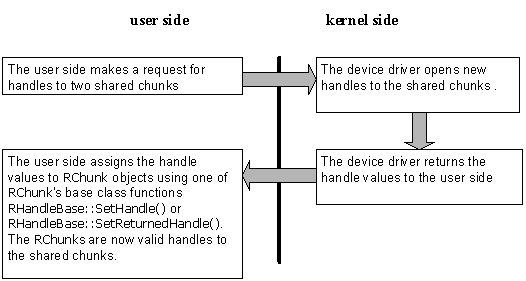
Device driver (kernel) side
This is example code snippet shows the device driver side handling of the request made by the user-side to open handles on two shared chunks.
The request is handled by the OpenIoChunks() function in the device driver's logical channel. The logical channel is represented by a class derived from DLogicalChannelBase. In this example, this is the DMyDeviceChannel class.
Details of how a user-side call to RMyDevice::OpenIoChunks() results in a call to the driver's DMyDeviceChannel::OpenIoChunks() function are not shown. Passing requests from user-side to kernel-side in The Logical Channel explains the principles.
/** Kernel-side Logical Channel for 'MyDevice' */ class DMyDeviceChannel : public DLogicalChannelBase { ... private: TInt OpenIoChunks(RMyDevice::TIoChunkInfo* aIoChunkInfoForClient); private: DChunk* iInputChunk; TInt iInputChunkSize; DChunk* iOutputChunk; TInt iOutputChunkSize; ... };
The following code snippet is the implementation of DMyDeviceChannel::OpenIoChunks().
/** Called by logical channel to service a client request for i/o chunk handles */ TInt DMyDeviceChannel::OpenIoChunks(RMyDevice::TIoChunkInfo* aIoChunkInfo) { // Local info structure we will fill in RMyDevice::TIoChunkInfo info; // Need to be in critical section whilst creating handles NKern::ThreadEnterCS(); // Make handle to iInputChunk for current thread TInt r = Kern::MakeHandleAndOpen(NULL, iInputChunk); // r = +ve value for a handle, -ve value is error code if(r>=0) { // Store InputChunk handle info.iInputChunkHandle = r; // Make handle to iOutputChunk for current thread r = Kern::MakeHandleAndOpen(NULL, iOutputChunk); // r = +ve value for a handle, -ve value is error code if(r>=0) { // Store OutputChunk handle info.iOutputChunkHandle = r; // Signal we succeeded... r = KErrNone; } else { // Error, so cleanup the handle we created for iInputChunk Kern::CloseHandle(NULL,info.iInputChunkHandle); } } // Leave critical section before writing info to client because throwing an // exception whilst in a critical section is fatal to the system. NKern::ThreadLeaveCS(); // If error, zero contents of info structure. // (Zero is usually a safe value to return on error for most data types, // and for object handles this is same as KNullHandle) if(r!=KErrNone) memclr(&info,sizeof(info)); // Write info to client memory kumemput32(aIoChunkInfo,&info,sizeof(info)); return r; }
Implementation notes
The function calls Kern::MakeHandleAndOpen() twice, once for each shared chunk. A NULL value is passed as the first parameter in both calls to this function instead of an explicit DThread object. This creates the handles for the current thread. Although this code is running in kernel mode, the context remains the user thread.
The first handle created is closed if the second handle cannot be created:
if(r>=0) { ... } else { // Error, so cleanup the handle we created for iInputChunk Kern::CloseHandle(NULL,info.iInputChunkHandle); }
The handle values are written back into the TIoChunkInfo structure using the kumemput32() function. See the EKA2 references in Accessing User Memory in Migration Tutorial: EKA1 Device Driver to Kernel Architecture 2.
Example: Using a DFC to notify destruction of a chunk
This set of code snippets shows how to set up a DFC that notifies a device driver when a shared chunk has finally been destroyed.
/** Example class suitable for use as a 'Chunk Destroyed DFC' when creating Shared Chunks with Kern::ChunkCreate() */ class TChunkCleanup : private TDfc { public: TChunkCleanup(DMyDevice* aDevice); void Cancel(); private: static void ChunkDestroyed(TChunkCleanup* aSelf); private: DMyDevice* iDevice; }; /** Contruct a Shared Chunk cleanup object which will signal the specified device when a chunk is destroyed. */ TChunkCleanup::TChunkCleanup(DMyDevice* aDevice) : TDfc((TDfcFn)TChunkCleanup::ChunkDestroyed,this,Kern::SvMsgQue(),0) , iDevice(aDevice) {} /** Cancel the action of the cleanup object. */ void TChunkCleanup::Cancel() { // Clear iDevice which means that when the DFC gets queued on chunk destruction // our ChunkDestroyed method will do nothing other than cleanup itself. iDevice = NULL; } /** Callback function called when the DFC runs, i.e. when a chunk is destroyed. */ void TChunkCleanup::ChunkDestroyed(TChunkCleanup* aSelf) { DMyDevice* device = aSelf->iDevice; // If we haven't been Cancelled... if(device) { // Perform any cleanup action required. In this example we call a method // on 'MyDevice' which encapsulates this. device->ChunkDestroyed(); } // We've finished so now delete ourself delete aSelf; }
Implementation notes
The DFC is an item of information that is passed to Kern::ChunkCreate() when the shared chunk is created. See Example: Creating a shared chunk to see how the two sets of code connect.
Ensure that the code implementing this DFC is still loaded when the DFC runs. As you cannot know when a chunk will be destroyed, the code should reside in a kernel extension.
This code snippet shows how memory is committed. It is based on the implementation of the class DBuffers, which represents a group of buffers hosted by a single chunk.
/** Class representing a group of buffers in the same chunk */ class DBuffers { public: DBuffers(); ~DBuffers(); TInt Create(TInt aBufferSize,TInt aNumBuffers); public: DChunk* iChunk; /**< The chunk containing the buffers. */ TLinAddr iChunkKernelAddr; /**< Address of chunk start in kernel process */ TUint32 iChunkMapAttr; /**< MMU mapping attributes used for chunk */ TInt iBufferSize; /**< Size of each buffer in bytes */ TInt iOffsetToFirstBuffer; /**< Offset within chunk of the first buffer */ TInt iOffsetBetweenBuffers; /**< Offset in bytes between consecutive buffers */ };
/** Constructor */ DBuffers::DBuffers() : iChunk(NULL) {} /** Destructor */ DBuffers::~DBuffers() { if(iChunk) Kern::ChunkClose(iChunk); } /** Create the chunk and commit memory for all the buffers. @param aBuffserSize Size in bytes of each buffer @param aNumBuffers Number of buffers to create */ TInt DBuffers::Create(TInt aBufferSize,TInt aNumBuffers) { // Round buffer size up to MMU page size aBufferSize = Kern::RoundToPageSize(aBufferSize); iBufferSize = aBufferSize; // Size of one MMU page TInt pageSize = Kern::RoundToPageSize(1); // We will space our buffers with one empty MMU page between each. // This helps detect buffer overflows... // First buffer starts one MMU page into chunk iOffsetToFirstBuffer = pageSize; // Each buffer will be spaced apart by this much iOffsetBetweenBuffers = aBufferSize+pageSize; // Calculate chunk size TUint64 chunkSize = TUint64(iOffsetBetweenBuffers)*aNumBuffers+pageSize; // Check size is sensible if(chunkSize>(TUint64)KMaxTInt) return KErrNoMemory; // Need more than 2GB of memory! // Enter critical section whilst creating objects NKern::ThreadEnterCS(); // Create the chunk TChunkCreateInfo info; info.iType = TChunkCreateInfo::ESharedKernelMultiple; info.iMaxSize = (TInt)chunkSize; info.iMapAttr = EMapAttrCachedMax; // Full caching info.iOwnsMemory = ETrue; // Use memory from system's free pool info.iDestroyedDfc = NULL; TInt r = Kern::ChunkCreate(info, iChunk, iChunkKernelAddr, iChunkMapAttr); if(r==KErrNone) { // Commit memory for each buffer... TInt offset = iOffsetToFirstBuffer; // Offset within chunk for first buffer // Repeat for each buffer required... while(aNumBuffers--) { // Commit memory at 'offset' within chunk r = Kern::ChunkCommit(iChunk,offset,aBufferSize); if(r!=KErrNone) break; // Move 'offset' on to next buffer offset += iOffsetBetweenBuffers; } if(r!=KErrNone) { // On error, throw away the chunk we have created Kern::ChunkClose(iChunk); iChunk = NULL; // To indicate that 'this' doesn't have any valid buffers } } // Finished NKern::ThreadLeaveCS(); return r; }
Copyright ©2010 Nokia Corporation and/or its subsidiary(-ies).
All rights
reserved. Unless otherwise stated, these materials are provided under the terms of the Eclipse Public License
v1.0.